Evolving the IBM Cloud Console with Microservices: A Node.js Success Story
Learn how the IBM Cloud console architecture evolved from its monolithic origins into a highly scalable, modern microservice-based system, and the role Node.js played.
Introduction
The IBM Cloud console provides the web front end for IBM Cloud, an open and secure public cloud providing enterprise-class IaaS and PaaS capabilities with over 170 managed services covering data, AI, IoT, security, blockchain, and more. I’ve had the pleasure of working on the console for most of the last decade. As a more junior developer, I wrote the first lines of proof-of-concept front-end code before IBM Cloud even had a name. This cloud was made generally available as IBM Bluemix in 2014, rebranded as IBM Cloud in 2017, and incorporated the fully integrated SoftLayer experience in 2018.
I became the lead full-stack architect in 2014, and had the opportunity to work with a countless number of talented developers, UI designers, and offering managers as the console’s architecture and user experience (UX) were regularly updated and improved to keep pace with the maturing IBM Cloud. Last year, I left this amazing team for another role as an architect on the IBM Cloud for Financial Services. As I reflect on the experience, I’ll share with you how the console architecture has evolved from its monolithic origins into a highly scalable, modern microservice-based system composed of dozens of micro front ends. In particular, I’ll highlight the critical role that Node.js played in this evolution.
What is the IBM Cloud console?
The IBM Cloud console serves as a UX consolidation point for the entire IBM Cloud ecosystem, with UIs contributed by more than 75 teams across IBM that cover a wide range of IBM Cloud features and functions. With these contributions, the console lets users create, view, and manage all of their IBM Cloud resources. It also provides a UX for a number of other core platform capabilities, including:
- Registration: Allows users to sign up for IBM Cloud
- Identity and access management: Lets users manage authentication and control access to IBM Cloud resources
- Account: Offers the ability to manage IBM Cloud accounts
- Catalog: Provides users the ability to view and order IBM Cloud offerings
- Billing/usage: Allows users to monitor their IBM Cloud usage and view their bill
- Support: Lets users request help and report problems
- Docs and API docs: Provides information on how to use IBM Cloud and IBM Cloud APIs
The following image shows the console’s dashboard.
Origins as a monolith
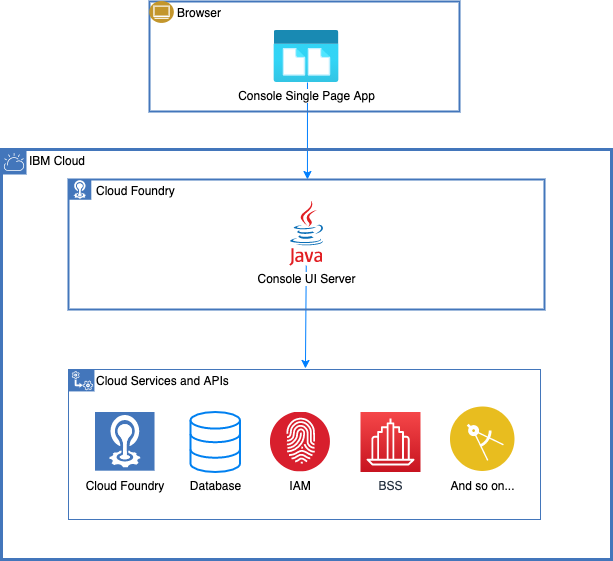
The original console was deployed to the IBM public Cloud Foundry instance as a single monolithic Java application on the back end. This application served APIs as well as the static resources for the monolithic front end that was written using the Dojo Toolkit. The front end was a single-page application (SPA) where all HTML, CSS, and JavaScript resources were loaded within a single web page. The front end made AJAX calls to consume APIs provided by the Java server. At the time, this monolithic Dojo/Java combination was one of the most common architectural patterns in IBM.
The following image shows the original architecture.
Cracks begin to show
The early console’s function was focused entirely around Cloud Foundry apps, services, and billing. A few development squads worked on the initial release, and generally things were going pretty well. However, cracks began to show in the monolithic architecture. Some of the issues included:
- Fragile code: Developers started to become afraid of making changes for fear of introducing unintended consequences and breaking the application.
- Lack of resiliency: The monolithic Java server was a single point of failure. If the Java back end went down, the entire UI was down. We had horizontal scaling in place with multiple instances and load balancing between them, but if null pointer exceptions, memory leaks, or other problems caused the instances to crash repeatedly, then the whole console was compromised.
- Small changes difficult to deploy: Code updates required building, testing, and redeploying the entire application, even for very small changes.
- Limited ability for other teams to contribute: The relatively small core console team was becoming a bottleneck for the ever increasing number of features demanded of a rapidly expanding cloud. Teams throughout IBM wanted to extend the console to include UIs for a multitude of additional compute types and managed services, but there was no easy way for them to extend the existing code base with new features.
- Locked into technology stack: The monolithic architecture locked us into using Dojo and Java. In particular, Dojo was beginning to lose favor within IBM as the world of front-end web development was exploding with interesting toolkits.
- Poor performance: The static resources of the Dojo-based SPA were large, and the volume of client-initiated AJAX requests to fill in page content led to unacceptable performance.
- Lack of search engine optimization (SEO): The HTML served by the SPA was really just a shell for loading required JavaScript and CSS. So, there was no content for web crawlers to process.
For these reasons, it became clear that the monolithic architecture was not going to scale to support our goals over the long term, and it was obvious that we needed a new direction.
New architecture to the rescue
Microservices and micro front ends
As we looked to break free of the constraints of the monolith, we settled on a microservices architecture with many smaller, loosely coupled services that we called “plug-ins.” Each plug-in would be a micro front end, or vertical slice representing a distinct area of responsibility within the overall UX. The plug-ins would be independent entities made up of client-side functions as well as a corresponding stateless, server-side backend-for-frontend (BFF) that would host the UI resources and provide any APIs needed by the front end. The composition of these plug-ins would form an experience that looked and behaved like one cohesive web application.
We expected this approach to provide numerous benefits, including:
- Allowing for paced migration: We had real users who expected existing functions to remain in place while also gaining new features. We couldn’t just start from scratch, nor could we pause development while taking the time to rewrite our entire codebase. The microservices architecture would let us continue running the monolith while we steadily broke apart its features into micro front ends that would run alongside it.
- Limited blast radius for changes: In general, new bugs would be isolated to one plug-in and not break other plug-ins.
- Increased resiliency: The single point of failure of the monolith would be eliminated. So, if the instances of a plug-in started crashing, the rest of the console could still run.
- More granularity when deploying updates: Plug-ins would be deployed independently, so teams would have the freedom to fix issues or make enhancements on their schedule without requiring the entire console to be rebuilt and redeployed.
- Improved cross-team contributions: Plug-ins could be provided by any squad who wanted to build one. This eliminated the bottleneck of a single team being responsible for developing and maintaining a monolith.
- Flexibility in technologies: The base architecture didn’t require that a plug-in use a particular technology stack. This would free us from Java and Dojo, and let teams make technology decisions for their back-end and front-end code that made sense for them.
- Better performance: Instead of one large monolithic SPA, emphasis would be placed on building small services optimized for speed and page size. Perceived performance would be improved by generating more content on the server and sending in the initial HTML payload to ensure that key parts of the page were in place on initial rendering. In addition, pages would try to use vanilla JavaScript where possible. And, where vanilla JavaScript wasn’t feasible, pages would use only lightweight frameworks.
- Improved SEO: With more content being generated on the server, web crawlers would be able to index the parts of the console that we wanted to appear in search engine results.
Prominent role of Node.js
Even though one of the selling points of the new architecture was flexibility in technology choice across the plug-ins, we didn’t want to create a wild west with every plug-in making different choices. We recognized that being strongly opinionated in some areas would increase efficiencies in code reuse and enable knowledge transfer as developers moved between plug-in squads.
To that end, we made a key early decision to strongly recommend Node.js for back-end microservice development. Node.js was a great fit for several reasons, including:
JavaScript runtime: JavaScript is relatively easy to learn, and it’s used by nearly 68% of all developers (according to the 2020 Stack Overflow survey.
- Transfer of skills up and down the stack: The use of JavaScript would enable our developers to transfer front-end JavaScript skills to the back end, and vice versa. This meant developers would be able to effectively work on the full stack without having to become proficient in a second language.
- Robust ecosystem: We believed developers would be able to do more, with less effort by virtue of the rich Node.js ecosystem. For example, the public NPM registry includes thousands (now millions) of open source tools and modules written and supported by developers all over the world.
- Well-suited for our workloads: Node.js would be able to handle the demands of our highly scalable, non-CPU intensive BFFs by virtue of it being optimized as an asynchronous event-driven runtime.
Micro front end architectural pattern
The diagram shows the general micro front-end architectural pattern that was proposed.
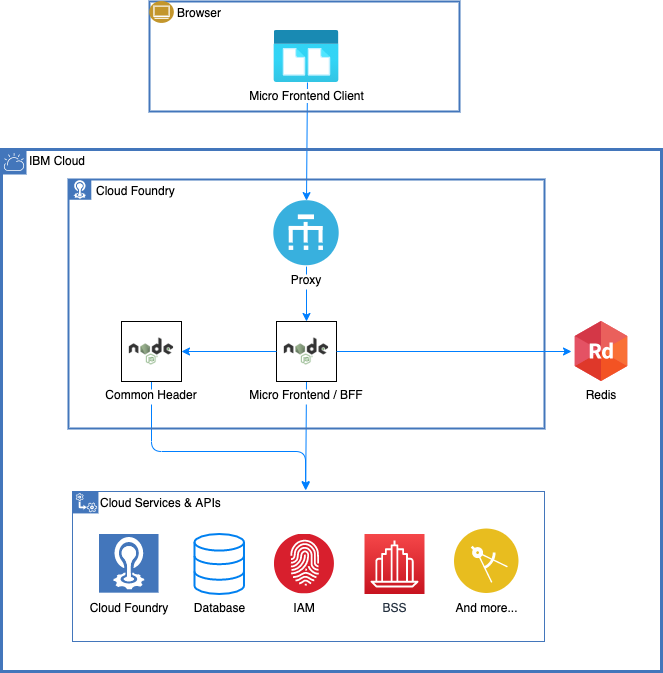
The pattern’s flow (based heavily on work done by colleague Dejan Glozic) involved the following steps:
- The page request comes into server-side proxy.
- The proxy routes the request to the appropriate Node.js microservice based on the URL (for example, a request for
/catalogwould get routed to our Catalog microservice acting as the BFF for the Catalog UI). - The microservice handles the request to return HTML to the client:
- Consults the shared session store (for example, Redis) for the user token (which would have been inserted in cache during the login process).
- Collects information needed for the initial page rendering by invoking back-end IBM Cloud APIs, other microservices, databases, and so on. Special attention would need to be paid here to not make expensive calls on the server-side that would delay the HTML response and leave the user seeing a blank screen for an extended period.
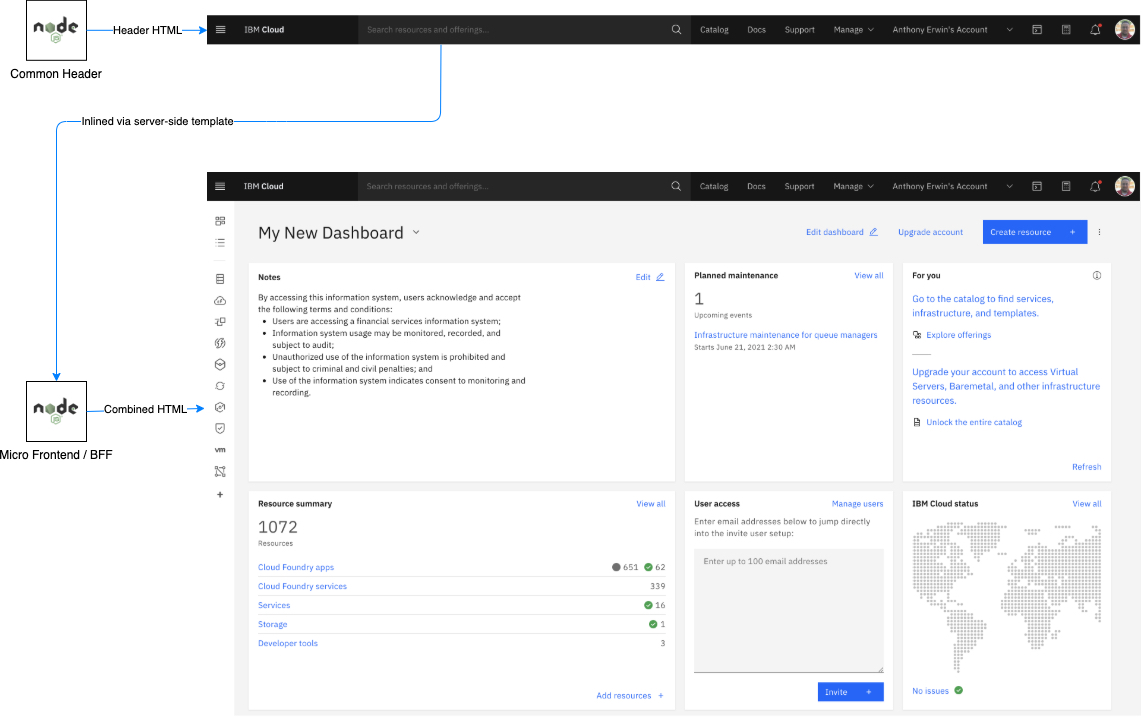
- Invokes the Common Header API (provided by a special purpose microservice) to get HTML for a shared header to include in the initial payload.
- Uses server-side templating to insert all data into one HTML payload.
- The browser renders the pages and loads any required (and hopefully lightweight) JavaScript and CSS.
- The page might then make additional API calls back to the BFF to get additional data and execute user-initiated actions.
The insertion of the common header is one of the most important parts of the process. All of the pages in the console, regardless of what service produced them, needed to look like they were part of one seamless application. Including the same header on every page would serve to unify the entire experience. This is shown in more detail in the following image.
Executing the migration from monolith to microservices
Armed with these ideas and the dreams of numerous benefits, we started down the path of transitioning to the new architecture. One problem every team faces when migrating from monolith to microservices is determining how best to partition the existing monolith into microservices. Unfortunately, there’s no one-size-fits-all paradigm for making this determination, and it’s often more art than science.
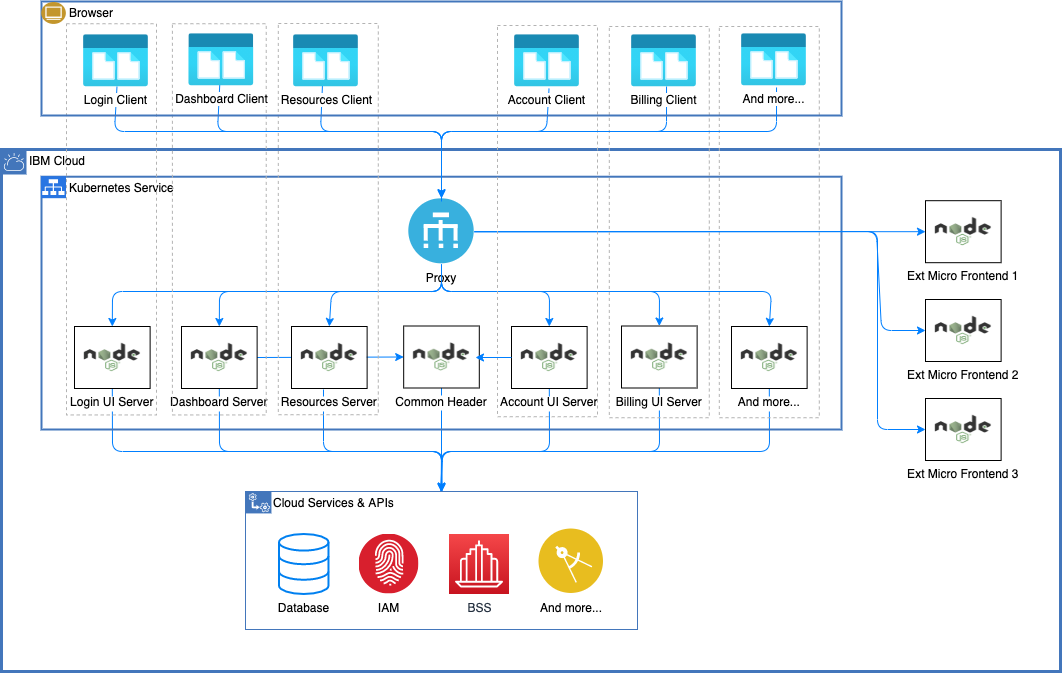
In our case, we wanted to start small, and we chose two relatively simple, mostly static parts of our UI – the home page and marketing solutions pages – for the initial proof-of-concept (PoC). The following image shows that architecture.
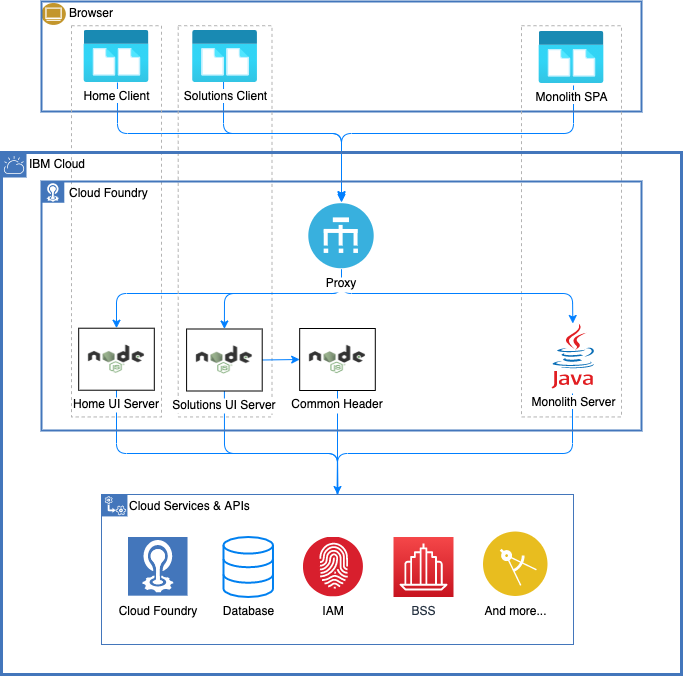
In the image, you see that we added a proxy plus micro front ends for Home, Solutions, and Common Header. Additionally, the Java monolith continued to run alongside these new microservices. As alluded to earlier, it was key that we could stage the migration to the new architecture because it wasn’t feasible to start over. This meant slowly breaking out logical pieces of the monolith and rewriting them for the new architecture.
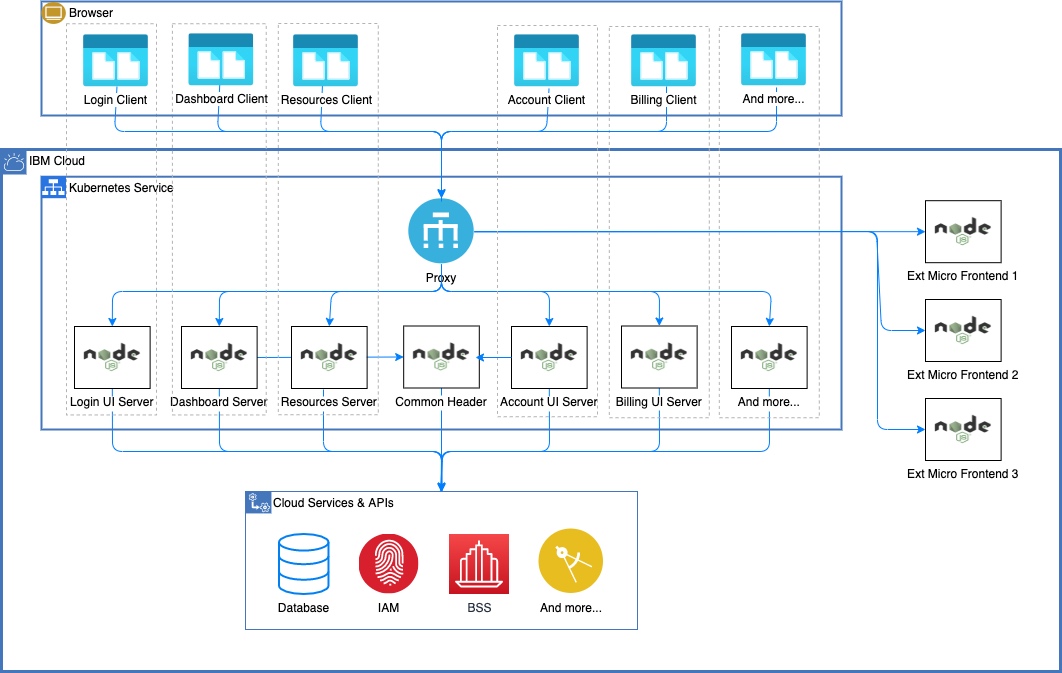
Over the course of the next two years, we were able to entirely eliminate all vestiges of the original monolith and complete the migration to the new architecture. We were also able to greatly increase the number of developers and teams who could independently contribute plug-ins to the larger console on their own schedules. This was done by enabling the console proxy to route requests outside of the console cluster and out to microservices deployed and managed by other teams. All of this can be seen in the following figure:
New challenges
You might think the story is over at this point – that we knew it all, the migration was easy, and everything has been smooth sailing ever since. But, make no mistake, there have been plenty of growing pains both during those first couple of years of migration and the few years since. Developing and running a scalable, resilient, highly available, performant microservice-based architecture on the cloud is hard. I’ve often joked that if we knew all of the problems we’d encounter along the way, we might not have done it at all.
But, of course, no one and no team can know everything up front, nor can a team do everything they’d like to all at once. Being agile enough to make mid-course corrections based on new information and new challenges is critical. To that end, the console architecture and ecosystem have not stayed static and continue to evolve today. The next several sections explore some of the major challenges that popped up, and how the team rose to the occasion to address them. Despite the challenges, the path we chose has paid off immensely.
Enabling console developers
One of our initial goals was to enable a large ecosystem of console developers from both the core console team as well as other teams from across IBM Cloud. In the early days, we had a few samples and reusable Node.js modules. This got us by, but we needed to make developing console plug-ins more efficient and as self-service as possible in order to scale.
So, over the years, we’ve built a pretty robust set of console developer resources. These include assets and processes needed for UI developers to quickly and easily build and maintain plug-ins, such as:
- Best practices and guidelines
- Node.js starter app
- Reusable UX patterns and components
- NPM modules for enabling session management
- Console APIs (and associated Swagger docs)
- Plug-in extension points
- End-to-end test framework
- CI/CD pipeline
Best practices and guidelines
We wanted to ensure that all plug-ins were held to the same high standards to ensure the best customer experience possible. A major part of achieving this goal was establishing a clear set of expectations and responsibilities required to participate in the console ecosystem.
These expectations were codified in a set of best practices in these areas:
- Onboarding
- UI design guidelines and reviews
- Coding standards
- Testing and monitoring
- Performance and reliability
- Security
- Accessibility
- Globalization and translation
- Documentation
- Incorporation of analytics tools
These plug-in best practices were made mandatory as part of the internal IBM Cloud Service Framework, which all service teams must be validated against before their offerings appear in the IBM Cloud catalog.
Opinionated Node.js starter app
One important requirement we levied is that new plug-ins must be based on a minimal standard UI starter app written with Node.js. The starter app includes everything needed for a basic micro front end and is intended to help developers adhere to the best practices laid out in the previous section. The starter uses the Express web application framework and pulls in custom modules acting as Express middleware to enable authentication, session management, and so on.
In support of front-end development, the starter includes packages for:
- Carbon Design System: The IBM external open source design system for products and digital experiences. With the IBM Design Language as its foundation, the system consists of working code, design tools and resources, human interface guidelines, and a vibrant community of contributors.
- Cloud Pattern and Asset Library (PAL): Internal to IBM, this library provides service team developers with reusable React components and hooks to build user interfaces on IBM Cloud. The library is built using the Carbon Design System and components from Carbon Components React to create other components and patterns that are consistent across IBM Cloud.
- webpack: This is used to produce nicely packaged modules of UI resources that can be served to the browser.
The use of these UI libraries is a key element in promoting uniformity and consistency in the UX, while still giving teams freedom to be creative.
The starter highlights the power of the Node.js module system and support of build-time tools. Developers can run the starter app locally in a way that makes it seem like it is part of a development deployment of the full console. With that, we’ve found that developers can take the starter app and quickly become productive.
CI/CD pipeline
The importance of a robust CI/CD pipeline was one of the biggest things we underestimated, especially as the number of microservices increased. But, over time, we built a pipeline for the console that we’re proud of – so much so that we now strongly encourage all plug-in teams to use the pipeline rather than build their own. We still support routing proxy requests to externally hosted plug-in deployments, but teams who have integrated with this central pipeline have saved countless hours of development and maintenance.
The pipeline features:
- Easy onboarding where the plug-in team simply provides a GitHub repo containing their microservice code
- Automatic builds as code is pushed to GitHub
- Enablement of rolling deployments through development, test, and production environments
- Automatic deployment in all console clusters around the world
- Ability to promote individual microservices on demand
- Vulnerability scanning of container images
- Integration of build, unit, and end-to-end testing to help improve quality
- Red/black deployments giving both on-deck and live environments that allow for quick reverts to the previous code in case something goes wrong
The pipeline now deploys nearly 100 independent microservices per console deployment.
Monitoring and troubleshooting
We also greatly underestimated the importance of monitoring and troubleshooting when microservices were introduced. If you’ve worked on UIs, you know that defects often get routed to the UI team first regardless of where the problem might be in the system. I’ve often referred to the console as the “canary in the mine shaft” for IBM Cloud as a whole. Because it acts as the front end to IBM Cloud, anything not working correctly in any part of IBM Cloud probably impacts some part of the console.
It became a matter of self-preservation to add monitoring so that we could quickly:
- Determine whether the problem was actually in the console or elsewhere in the cloud
- Identify which microservices might be implicated
- Troubleshoot and fix any console problems that were found
In the early days of our microservice migration, we developed a bespoke monitoring system to track status codes and response times for every inbound/outbound request on every microservice with results available in Grafana dashboards. After this system was in place, we were no longer “flying blind” and were often able to identify problems in various parts of IBM Cloud even before the affected teams knew there was an issue.
The system has evolved, but is still in place today. One of our most recent and important changes was to leverage OpenCensus (now merged with OpenTelemetry). This has enabled us to construct distributed traces in Jaeger to see how requests flow from microservice to microservice in our system.
Improved high availability and resiliency
Moving to a microservice architecture was important for high availability and resiliency. However, that alone did not get us where we wanted to be. There were two other changes made that took our availability to the next level that had nothing to do with microservices or Node.js. I bring this up because even with the most solid of microservice architectures, you still need to think about how you deploy the system to achieve your availability goals.
Adopting Kubernetes
You might recall that our first microservices architecture ran on Cloud Foundry. A critical part of the evolution of the console was replatforming to the IBM Cloud Kubernetes Service. We moved to Kubernetes because it allowed us to achieve greater performance, scalability, reliability, and security than we had on Cloud Foundry.
Each console deployment uses a Kubernetes cluster with 9 worker nodes running on 16 cores with 64 GB of memory.
Geo-load balancing and failover
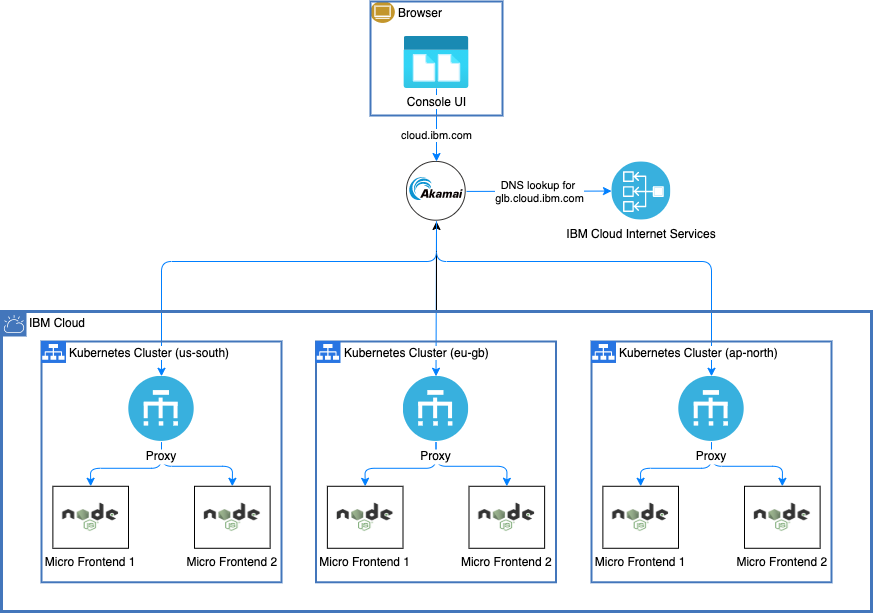
The decision that made an even greater impact on our availability was implementing geo-load balancing and failover. This basically means routing a user’s request to the geographically closest console deployment which is also healthy. The odds of all deployments being unhealthy at the same time is much less than one deployment being unhealthy.
The production console is deployed to clusters in 9 different regions all around the world. IBM Cloud Internet Services monitors the health of these deployments through a health check endpoint on each cluster provided by the console team. When a request goes to our single global URL (https://cloud.ibm.com), Cloud Internet Services returns the IP address for the nearest console deployment. If a health check in a particular region shows a problem, then Cloud Internet Services returns the IP address for the next closest healthy region.
Conclusion
I’m now in a new role, but it’s amazing to look back and see how far we’ve come since our monolithic beginning. There were challenges moving to a microservices architecture and the evolution since, but the benefits have far outweighed the problems. We’ve seen dramatic benefits in terms of improved resiliency, performance, developer productivity, and ability to incorporate plug-ins from teams across IBM Cloud.
The architecture continues to evolve, and there are things we’d do differently today based on what we’ve learned. But, of all of the decisions we’ve made along the way, we never regretted basing our microservices on Node.js. It was and continues to be the right runtime for the job and has enabled the console to become a true Node.js success story.
Acknowledgements
Special thanks to all of the amazing architects, developers, UI designers, and offering managers who have worked so hard over the years to make the console what it is today. It’s truly been a collaborative team effort, and I’m thankful I got to be a part of it.
Update 4/6/23: This blog was originally published on the IBM Developer site, and I had posted only an excerpt here. But, IBM Developer decided to archive the original, so now I’m including the full text on my site.